Nr 5/2004 (56), Public relations w bibliotekach. Badania, teorie, wizje
Nr 5/2004 (56), Public relations w bibliotekach. Badania, teorie, wizje |
|
Andrzej Koziara
| |||
Kolejny rok - kolejne kłopoty. Tak właściwie można rozpocząć każde wystąpienie. Zarówno to dotyczące finansowania działalności, jak i organizacji pracy czy budowania modeli technologicznych systemów komputerowych. Tym bardziej, że kolejne lata naszej działalności ukazują, jak ważne jest prawidłowe liczenie kosztów prowadzonych przez nas przedsięwzięć. Okazuje się, że modele zarządzania oparte na filozofii TQM (Total Quality of Management - zarządzanie poprzez jakość) czy szczegółowo na zasadach liczenia kosztów TCO (Total Cost of Ownership - całkowity koszt posiadania) wymagają przygotowania bardzo szczegółowych modeli technologicznych wdrażanych przedsięwzięć. Jak pokazuje praktyka, może być to szczególnie znaczące dla przedsięwzięć o bardzo szerokim zakresie, rozproszonych we wdrażaniu, zarządzaniu, jak i zasięgu spodziewanych efektów. Przeprowadzane drobiazgowe analizy problemów informatycznych prowadzą do wniosków, że jednym z największych elementów składowych kosztów jest praca ludzka, szczególnie ta, która w sposób rozproszony jest dublowana, a więc ekonomicznie nieuzasadniona. Szczególne miejsce w tych analizach mają prace związane z teorią i praktyką hurtowni danych. Pojęcie hurtowni danych powstało w chwili, gdy niezbędnym stało się znalezienie sposobu na jednolity dostęp do danych gromadzonych w różnych bazach danych. Wiele z problemów definiowanych w teorii hurtowni danych nie dotyczy bibliotek (może z pominięciem pomysłu scalania nienormatywnych baz katalogowych w ramach podbazy systemu NUKAT), lecz jest jeden obszar, który szczególnie nas interesuje. Jest nim utrzymanie spójności danych. Główną inspiracją do przygotowania tegoż opracowania stały się prace studialne nad synchronizacją systemów informatycznych. Praktycznym przykładem są studia projektowe nad systemem bramek umożliwiających wymianę informacji pomiędzy systemami dziekanatowymi a systemem bibliotecznym. W związku z unormowaniami prawnymi, związanymi z ochroną danych osobowych, oraz projektami jednolitego dostępu do nich podjęliśmy studia nad możliwościami wymiany danych pomiędzy systemami bazodanowymi pracującymi z wykorzystaniem produktów różnych firm (Oracle, Progress, Microsoft czy IBM). Wnioski z podjętych prac oraz wiele innych przykładów komercyjnego upowszechniania dostępu do systemów rozpowszechniania informacji (np. wysyłanie SMS'ów przy pomocy specjalnego oprogramowania) prostą drogą prowadzi do kolejnych analiz systemowych. Jedną z nich jest stworzenie wizji technologicznej modelowego, a co najważniejsze przygotowanego do dalszej rozbudowy systemu do obsługi katalogu narodowego. System ten, jak założyłem, powinien pełnić dwie funkcje:
W związku z tym, w artykule nie zajmę się żadnymi aspektami bibliotekarskimi, dotyczącymi struktur definiowanych w normach. Równocześnie będę w nim wykorzystywał wszelkie ustalenia merytoryczne z pracy zespołów fachowców, które to zdefiniowały standardy informacji umieszczanej w naszym katalogu narodowym NUKAT. Artykuł ten nie ma być w żaden sposób polemiką z ich ustaleniami, lecz jego zadaniem jest tworzenie wizji narzędzia, w którym wszelkie ustalenia merytoryczne w sposób szybki i naturalny znajdowałyby swoją realizację. Przyjęte przeze mnie priorytety decydują o tym, że podstawowymi założeniami przy tworzeniu modelu systemu informatycznego, obsługującego katalog narodowy, są:
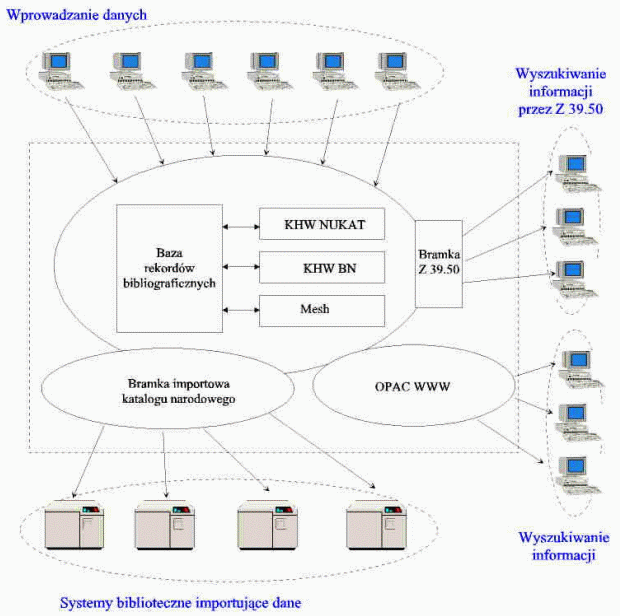
Model funkcjonalny systemu opracowanego na bazie powyższych założeń można przedstawić następująco:
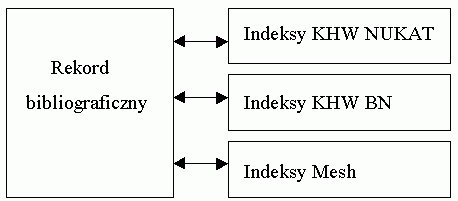
Rys. 1. Model funkcjonalny systemu informatycznego. Już na pierwszy rzut oka widać, że zawiera on klasyczne elementy zaawansowanego merytorycznie i technologicznie systemu bibliotecznego oraz uzupełniające go moduły wprowadzone jako dodatkowe elementy systemu, konieczne dla przystosowania go do funkcji sprawnej dystrybucji rekordów bibliograficznych. Jak myślę, elementy oprogramowania związane z klasycznymi funkcjami systemu bibliotecznego nie wymagają szerszego omawiania. Z rozwiązaniami funkcjonalnymi, oferowanymi przez systemy biblioteczne, możemy się zapoznać np. poprzez uważne przestudiowanie ich dokumentacji lub korzystając z marketingowych informacji firmowych. Dla zrozumienia późniejszych rozważań pewną uwagę powinniśmy na wstępie poświęcić analizie struktury bazy bibliograficznej. Z założeń projektowych wynika, że zespół pracujący nad stworzeniem struktury bazy bibliograficznej, opartej równolegle lub zamiennie na trzech bazach pomocniczych, musiał uporać się z dużymi trudnościami merytorycznymi. Jednak wyniki jego pracy są idealną podstawą do stworzenia startowego modelu systemu katalogu narodowego. Jak wynika z rezultatów ich pracy, rekord takiej bazy możemy bardzo ogólnie przedstawić jako zespół danych składający się z rekordu bibliograficznego, zawierającego pola będące relacyjnymi powiązaniami do rekordów pochodzących z "baz indeksowych" oraz tych, których zawartość jest wprowadzana "z palca" podczas jego opracowywania. Model ten oczywiście jest tylko schematyczny i nie oddaje rzeczywistej złożoności relacji zachodzących pomiędzy rekordem bibliograficznym a pomocniczymi "bazami indeksowymi", jak również relacji, które zachodzą w samych bazach indeksowych:
Rys. 2. Schemat relacji zachodzących pomiędzy rekordem bibliograficznym a pomocniczymi "bazami indeksowymi". Problemy te, nieznajdujące się w sferze moich obecnych zainteresowań, w przyszłości mogą stanowić doskonały materiał do kolejnego opracowania analitycznego wspomagającego zmiany w systemach bibliotecznych. Zasadniczą rolę w racjonalnym wykorzystaniu danych z baz współtworzonych przez pracowników wielu bibliotek powinny stanowić tzw. bramki dystrybucyjne. Konstrukcja oprogramowania i jego możliwości w decydujący sposób kształtują realne koszty pozyskiwania i aktualizacji jednolitej i spójnej informacji. Oczywiście jest to miejsce, gdzie nie możemy się ograniczyć tylko i wyłącznie do rozwiązań standardowych i znormalizowanych w skali światowej. Musimy tutaj podjąć bardzo ważną decyzję, decyzję opartą o analizę możliwości wykorzystania rozwiązań standardowych, implementowanych w klasyczne systemy biblioteczne (np. Z39.50). Wstępne oceny założeń, na jakich opierano konstrukcję unormowanych systemów swobodnej wymiany danych, wskazują na to, że, niestety, nie mogą one stanowić podstawy do konstrukcji systemu przystosowanego do automatycznej synchronizacji zawartości baz danych. Jak się wydaje, rozwiązaniem tak postawionego problemu jest zaprojektowanie i wdrożenie samodzielnego systemu nazwanego przeze mnie serwerem dostępowym. Powinien on zostać wyposażony w następujące elementy:
Powstający w ten sposób system, mający tak szerokie możliwości udostępniania rezultatów współkatalogowania zbiorów, prowadzonego przez pracowników bibliotek aktywnie uczestniczących w procesie tworzenia bazy bibliograficznej, oczywiście musi zostać w prawidłowy sposób wykorzystany przez systemy biblioteczne bibliotek współpracujących z katalogiem narodowym. Szeroki zakres możliwości dystrybuowania informacji decyduje o możliwości zdefiniowania różnych modeli pobierania i aktualizacji rekordów bibliograficznych. Będą się one różnić technologicznie i jakościowo, choćby poprzez wykorzystywane w nich pomocnicze "bazy indeksowe". Dla zaprezentowania możliwości tak przygotowanego systemu katalogu narodowego przytoczę kilka zupełnie przypadkowo skonstruowanych trybów współpracy z nim lokalnych systemów bibliotecznych.
Analizując stan Biblioteki Uniwersytetu Śląskiego na początku 2004 roku, sądzę, że modelem najbliższym dla nas byłby ten wyspecyfikowany w punkcie pierwszym. W modelu takim BUŚ i nasz system biblioteczny pracowałby w następujący sposób:
Tak sformułowane założenia, specyfikujące możliwości pozyskiwania rekordów z katalogu narodowego, przygotowujemy dla każdego z wcześniej wyspecyfikowanych modeli pracy. Oczywiście jest jeszcze jeden najważniejszy warunek praktycznego zastosowania katalogu narodowego. Producenci systemów bibliotecznych muszą przygotować moduły wykorzystujące możliwości bramki importowej. Oprócz życzliwego podejścia do dodatkowych zadań, jakie narzucimy producentom systemów bibliotecznych, wiąże się to również z aspektami prawnymi, a w szczególności z zastosowaniem ustawy o prawie autorskim i prawach pokrewnych. System będzie spełniał swoją rolę tylko i wyłącznie wtedy, kiedy będzie możliwość dynamicznej zmiany cech użytkowych oprogramowania bramki. Dlatego też niezbędne jest zagwarantowanie prawne własności oprogramowania wraz z kodami źródłowymi dla instytucji zarządzającej systemem katalogu narodowego. |
| |||