Opracowanie przedmiotowe dokumentów
z zakresu nauk ścisłych: matematyczno-przyrodniczych i technicznych.
Język haseł przedmiotowych KABA:
teoria, praktyka, przyszłość
Kazimierz Dolny, 20-22 września 2006
Opracowanie przedmiotowe dokumentów z zakresu nauk ścisłych: matematyczno-przyrodniczych i technicznych. Język haseł przedmiotowych KABA: teoria, praktyka, przyszłość Kazimierz Dolny, 20-22 września 2006 |
Poprzedni - Spis treści - Następny
Veslava OsinskaInstytut Informacji Naukowej i Bibliologii UMK Współczesna problematyka sposobów klasyfikacji informatyki. Kierunki rozwoju
|
|
A. Literatura Ogólna B. Hardware C. Zorganizowane systemy komputerowe D. Software E. Dane F. Teoria obliczeń G. Matematyczne metody obliczeń H. Systemy informacyjne I. Metodologie obliczeniowe J. Zastosowanie komputerów K. Środowisko obliczeniowe |
A. General Literature B. Hardware C. Computer Systems Organization D. Software E. Data F. Theory of Computation G. Mathematics of Computing H. Information Systems I. Computing Methodologies J. Computer Applications K. Computing Milieux |
Źródło: opracowanie własne
Kategorie sprzętu i oprogramowania są obecne w postaci podklas także w klasyfikacjach: Uniwersalnej Klasyfikacji Dziesiętnej (UKD) i Klasyfikacji Biblioteki Kongresu USA (LCC). W klasyfikacji LCC działy związane tematyką komputerową są „porozrzucane” po kilku głównych klasach. Na przykład „Inżynieria komputerowa i sprzęt” należy do klasy „T – Technologie”, a „Oprogramowanie” – do klasy „Q – Nauka”, podklasy „QA – Matematyka”. Uniknięcie takich „przeskoków” umożliwia klasyfikacja specjalistyczna, np. CCS. Przyjrzyjmy się zatem, jak wewnątrz pozostałych głównych klas klasyfikacji CCS zorganizowana jest tematyka dotycząca maszyn liczących oraz nowoczesnych technologii.
W klasie „C. Zorganizowane systemy komputerowe” dostępne są działy odnoszące się do architektury, projektowania sieci komputerowych oraz systemów rozproszonych. Ponadto są tu umieszczone informacje o architekturach procesorów równoległych, pojedynczych i mnogich strumieni danych (multiprocesorów) oraz o implementacji systemów komputerowych.
Odrębna klasa pod nazwą „E. Dane” poświęcona jest naukowym poszukiwaniom wydajnych sposobów przechowywania i przetwarzania danych. Udostępnia ona działy o strukturach, reprezentacjach, kodowaniu danych, a także teorię informacji, która powtarza się dalej w klasie H.
Kolejna klasa „H. Systemy informacyjne” obejmuje zagadnienia związane z przechowywaniem, zarządzeniem i wyszukiwaniem informacji oraz reprezentacją i zastosowaniem systemów informacyjnych. Kilka z podklas odnosi się bezpośrednio do aktualnych kierunków badań naukowych w zakresie bibliotek cyfrowych i sieciowych serwisów informacyjnych. Tematycznie zakres klasy pokrywa się ze współczesną problematyką informacji naukowej. W takim razie informacja naukowa istnieje jako główna klasa klasyfikacji CCS. Badanie procesów informacyjnych zachodzi z wykorzystaniem gotowych produktów informatycznych (np. oprogramowania, sieci, maszyn); liczne przykłady z życia zawodowego dowodzą, iż granica pomiędzy informatyką a informacją jest rozmyta. Nieprzypadkowo te dwie dziedziny: zarówno komputery, jak i informacja naukowa, są połączone w obrębie jednej z głównych klas 000 Klasyfikacji Dziesiętnej Dewey’a (KDD).
Jak na obecny stan rozwoju i zastosowania nauk komputerowych, niezbyt zrozumiałe jest kryterium grupowania kategorii w kolejnej klasie „I. Metodologie obliczeniowe”. Nazwa zdecydowanie niewystarczająco charakteryzuje i integruje wymienione tu kierunki badań i zawarte treści odnośników. Równolegle do podklasy „Sztuczna Inteligencja”-SI, figuruje „Grafika komputerowa”, „Symulacja i Modelowanie”, „Przetwarzanie dokumentów i tekstu”, „Rozpoznawanie obrazów” itp. Ostatnie dwie kategorie są typowe dla zagadnień informacji naukowej, stąd powstaje skrzyżowanie gałęzi poziomu drugiego klas: H i omawianej.
W ostatniej dekadzie wzrósł stopień zaawansowania badań w kierunku konstruowania maszyn inteligentnych, rozwoju robotyki, projektowania i implementacji systemów eksperckich, dzięki czemu sztuczna inteligencja wyrasta na samodzielną dziedzinę nauki stosowanej, będącą na styku informatyki, neurologii, psychologii i technologii. Wydaje się zatem, iż powinna jej być przydzielona osobna główna klasa klasyfikacji. Niektórzy badacze SI, np. John Kingston[11], wypowiadają się za stworzeniem samodzielnej klasyfikacji SI, która byłaby odseparowana od ogólnych zagadnień informatyki. Podkategorie klasy SI to: „Aplikacje i Systemy Eksperckie”, „Programowanie automatów”, „Dedukcja i dowody teoretyczne” (Theorem Proving), „Metody i formalizmy reprezentacji wiedzy”, „Języki programowania i oprogramowanie”, „Uczenie się”, „Przetwarzanie języków naturalnych”, „Wyszukiwanie i metody kontroli”, „Robotyka”, „Systemy Percepcji Wizualnych” (Vision and Scene Understanding), „Rozproszona Sztuczna Inteligencja”.
W klasie „F. Teoria obliczeń” mieszczą się odsyłacze do zagadnień informatyki teoretycznej: generowanie formalnych, matematycznych modeli komputera i obliczeń, logika matematyczna i języki formalne, a także badania logiki i wartości intelektualnej programów komputerowych. Pokrewna tematyka z zakresu zastosowań matematyki w informatyce zawarta jest w sąsiedniej klasie „G. Matematyczne metody obliczeń”: obejmuje ona analizę numeryczną, teorię grafów, teorię prawdopodobieństwa i statystykę oraz oprogramowanie służące wymienionym zagadnieniom. Nauki przyrodnicze, medyczne i ich pochodne, a także wszystkie dziedziny wykorzystujące metody komputerowe należą do klasy zastosowań informatyki: „J. Zastosowanie komputerów”. Tematykę związaną z historią komputerów i obliczeń, edukacją informatyczną, ale również poruszającą aktualne aspekty społeczne i etyczne informatyki zrzesza klasa ostatnia: „K. Środowisko obliczeniowe”.
Przyjrzyjmy się, jak zorganizowana jest treść materiału w czwartej edycji Encyklopedii nauk komputerowych (Encyclopedia od Computer Science) z 2000 r. – niekwestionowanego w dzisiejszych czasach autorytetu w literaturze komputerowej i technicznej. Książka mieści zwięzłe objaśnienia najnowszych technologii informatycznych wraz z przykładami ich zastosowania w praktyce. Naświetlone są tu również historyczne motywy pojawienia się przełomowego punktu w rozwoju nauk komputerowych i technologii. Poruszanie bogatego zestawu zagadnień: perspektywy historyczne, aktualna wiedza i przewidywane trendy w bliskiej przyszłości lokuje encyklopedię na półce klasyki referencji naukowych. Rozdziały encyklopedii są pogrupowane następująco (p. Rys. 1):
Łatwo tu jest zauważyć bliską analogię do organizacji klas głównych klasyfikacji CCS. W konstrukcji taksonomii NK od wielu lat bierze udział ten sam skład osób (głównym redaktorem encyklopedii jest Anthony Ralston, który także tworzył wspólnie z innymi Taksonomię NK i Inżynierii) – widzimy tu konsekwentne trzymanie się zasady historycznej ciągłości w konstruowaniu schematu. Przedstawiony powyżej podział dla nauk komputerowych jest niemalże identyczny jak dekadę wcześniej powstały CCS. Nazwy większości klas (oprócz Hardware, Software i Teoria obliczeń) zmieniono na bardziej ogólnikowe i przejrzyste, dwie klasy o krzyżujących się gałęziach „Systemy Informacyjne” i „Dane” zostały połączone w jeden dział pod nazwą: „Informacja i Dane”.
Rys. 1. Organizacja rozdziałów w Encyklopedii Nauk Komputerowych
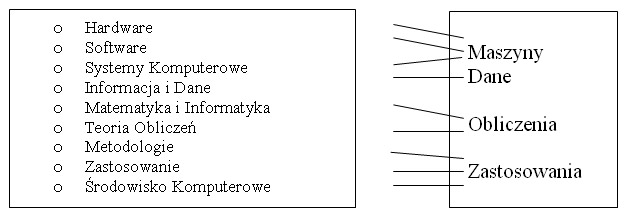
Źródło: opracowanie własne
Rozważania na temat rozwoju historycznego procesów obliczeniowych oraz współpracy człowieka z komputerem wymuszają pytanie o możliwości dalszej klasyfikacji zaprezentowanego podziału. Za cel postawimy sobie zadanie pogrupowania dziewięciu działów na wyższym poziomie. Wykorzystamy tu trzy wspomniane wcześniej grupy: maszyny, dane i obliczenia. Pierwsze trzy kategorie można byłoby przypisać do grupy maszyny, kategoria „Informacja i Dane” odnosiłaby się do grupy dane oraz do grupy obliczenia zaliczymy matematyczne metody w informatyce oraz informatykę teoretyczną (p. Rys. 1). Za pomocą pozostałych trzech kategorii: Metodologie, Zastosowanie i Środowisko wyszczególnione są możliwości zastosowań technologii komputerowych w różnych obszarach życia człowieka. Na dzień dzisiejszy utrwaliły się najważniejsze kierunki: sztuczna inteligencja, technologie Data Mining[12] i rozpoznawania obrazów, symulacja i modelowanie, grafika komputerowa, technologie informatyczne w przemyśle, medycynie, naukach ścisłych, kognitywnych oraz społecznych; oraz również bardzo ważna w społeczeństwie informacyjnym szybko rozwijająca się sfera edukacji informacyjno-informatycznej. Wszystko to są to rezultaty zarówno zespolenia różnych stref ludzkiej działalności naukowej i informacyjno-informatycznej, tak i interakcji pomiędzy człowiekiem a komputerem. W ostatnich latach ugruntowana została pozycja nowoczesnego interdyscyplinarnego przedmiotu „Interakcja człowiek – komputer” (Human-Computer Interaction HCI – brzmienie nawołuje do używania akronimu chińskiej litery XX CHI), który bada sposoby oddziaływania ludzkich procesów informacyjnych z procesami zautomatyzowanymi.
Dokonano próby rozpoznania wspólnych grup podziału logistyczno-empirycznego w zakresie informatyki, z uwzględnieniem historii przedmiotu. Moim zdaniem, takie lub podobne grupowanie może odgórnie zabezpieczyć braki w rzetelnej i szybkiej aktualizacji klasyfikacji nauk komputerowych, które przecież bardzo dynamicznie się rozwijają, a jednocześnie zachować główną strukturę drzewa klasyfikacji.
Pobieżne zapoznanie się ze współczesnymi tendencjami rozrostu gałęzi drzew klasyfikacji informatyki daje przegląd katalogów tematycznych ogólnodostępnych serwisów informacyjnych wyspecjalizowanych w dziedzinie nauk komputerowych i technologii. To preferencje użytkowników takich serwisów w dużej mierze decydują, które kategorie i podkategorie mają być bardziej rozbudowane, a które usunięte jako nieużyteczne. Można przypuszczać, iż różnorodność używanych schematów jest proporcjonalna do ilości rozpatrywanych serwisów - taką mieszaninę klasycznych i amatorskich klasyfikacji obserwujemy właśnie dzisiaj. Mimo że redaktorzy niektórych serwisów w trosce o ich aktualność na rynku informacji starają się stosować częste zmiany w strukturze (indeksacja z częstotliwością raz na tydzień), racjonalne rozwiązanie opiera się na technikach klasyfikacji automatycznej.
W nowoczesnych strategiach klasyfikacji automatycznej, która odzwierciadlałaby aktualny stan rozwoju nauk, panują dwa główne nurty: metody statystyczne oraz oparte na zarządzaniu wiedzą. Pierwszy jest przeznaczony do klasyfikowania dużych zasobów dokumentów i wykorzystuje automatyczne algorytmy kategoryzacji i klasteryzacji[13] tekstu. W algorytmach określa się wektor/wektory/mapę cech zbioru obiektów. W zależności od koncepcji badaczy, mogą nimi być słowa kluczowe, odległość pomiędzy wyrazami, sekwencje słów, semantyczne podobieństwa i relacje, hierarchia elementów, występowanie spójników, elementy graficzne z otaczającym tekstem, topologia obiektów, formaty i rozmiary plików.
Drugi nurt związany jest z technikami zarządzania wiedzą (knowledge-based) w bazach wiedzy i modulowaniu sieci semantycznych. Inżynieria wiedzy wymaga zazwyczaj ręcznego wkładu, co jest czasochłonne. Automatyzacja procesu klasyfikacji zachodzi na etapie populacji jej struktury danymi. Najlepsze wyniki, jak dotychczas, uzyskano w granicach wąskich domen[14]. W inżynierii wiedzy można spotkać się z przybliżeniem modelowania wielo-perspektywicznego (Multi-Perspective Modelling)[11]. Według autorów, pojedyncze ontologie[15] nie są w stanie przekazać pełnego opisu badanego obiektu, a zatem kompletna reprezentacja pojęcia lub obiektu wymaga użycia co najmniej sześciu ontologii, zbudowanych według cech lingwistycznych przymiotów: kto, co, jak, gdzie, kiedy i dlaczego, które mogą powtarzać się na różnych poziomach abstrakcji.
Kingston w swojej pracy[11] szczegółowo analizuje możliwości zastosowania teorii przybliżenia wielo-perspektywicznego do struktury klasyfikacyjnej CCS ACM. Kategorie klasyfikacji odpowiadają trzem różnym poziomom abstrakcji (p. Tab. 2).
Tab. 2. Podstawowe klasy CCS według przybliżenia wieloperspektywicznego
| Co | Jak | Dlaczego | Kiedy | Gdzie | Kto | |
| Zastosowania komputera | Zastosowania | Metodologie Komputerowe | ||||
| Wnętrze komputera | Hardware | Systemy Komputerowe | ||||
| Software | Dane | |||||
| Systemy Informacyjne | ||||||
| Poziom teoretyczny | Teoria obliczeń, Matematyczne metody obliczeń |
Źródło: Kingston, J. Ontology, Knowledge Management, Knowledge Engineering and the ACM Classification Scheme[11]
Niektóre dotyczą samego komputera oraz jego „wnętrza” (hardware, software, organizacja systemów komputerowych, dane, systemy informacyjne), inne komputer traktują jako samodzielne pojęcie w kontekście aplikacji obliczeniowych (metodologie obliczeniowe, aplikacje komputerowe, środowisko obliczeniowe). Trzeci poziom objawia się w dwóch teoretycznych kategoriach: „Teoria obliczeń” oraz „Matematyczne metody obliczeń”. Jest to kolejny przykład strukturyzacji klas klasyfikacji CCS, która tym razem opiera się na ontologii o przybliżeniu wielo-perspektywicznym.
Podejście ontologiczne w klasyfikacji licznych zbiorów dokumentów jest kluczem do modelowania sieci semantycznych. Dobrym rodzajem klasyfikacji dzisiaj jest taka, która odpowiada nie tylko bibliotekarzom – specjalistom danej dziedziny, lecz również zadowala stopniem aktualizacji, szybkością działania, ergonomicznym interfejsem użytkowników serwisów informacyjnych. Niezbędna w tym celu jest kombinacja omówionych powyżej i sprawdzonych metod klasyfikacji w połączeniu z mechanizmem zapewniającym dobrą interakcję z użytkownikiem. W obliczu szybko zachodzących zmian w strukturze, a w szczególności w hierarchicznych powiązaniach działów nauk komputerowych i im pokrewnych należy przede wszystkim kłaść nacisk na efektywne generowanie i aktualizowanie takiej struktury. Przydatny jest również mechanizm symulacyjny, pozwalający na automatyczną predykcję rozrostu poszczególnych gałęzi klasyfikacyjnych oraz automatyczne uzupełnianie poszczególnych pozycji w drzewie katalogowym.
Autorzy systemu CCS i osoby (mogą to być kompetentni użytkownicy serwisu) biorące udział w jego aktualizacji przy opracowaniu zmian doceniają znaczenie historycznych ciągłości zarówno w procesach wyszukiwania informacji, tak i dla poprawnego funkcjonowania obecnego oprogramowania. Każde unowocześnienie struktury wymaga włączenia elementów mapowania z zachowaniem archiwalnej integralności oraz ergonomiczności; struktura taka jednocześnie powinna być przejrzysta dla przeciętnego użytkownika przeszukującego zasoby. W raporcie Komitetu Aktualizacji CCS z 1998 r.[16] przytoczono wizję przyszłego systemu CCS na 2018 r. Ma być to dynamiczny system odzwierciedlający rzeczywistość przyszłych lat. Ma wykorzystywać porady systemów eksperckich dotyczące każdego przekroju branży NK, a także opierać się na technikach automatyzacji (np. statystyczna analiza kontekstu aktualnej literatury) możliwych zmian.
[1] SOSIŃSKA-KALATA, B. Struktury klasyfikacyjne w organizacji zasobów informacyjnych Internetu. In MISSI 2002: III Krajowa Konferencja – Multimedialne i sieciowe systemy informacyjne [on-line]. 2002 [dostęp 5 czerwca 2006]. Dostępny w World Wide Web: http://www.zsi.pwr.wroc.pl/zsi/missi2002/pdf/s403.pdf
[2] Katalog OPAC (Online Public Access Catalog) umożliwia szybkie i wielostronne wyszukiwanie różnego typu informacji.
[3] Tu jako porządek, systematyka klasyfikowanych obiektów z uwzględnieniem ich relacji.
[4] ACM Computing Classification System [on-line]. 1998 [dostęp 5 czerwca 2006]. Dostępny w World Wide Web: http://www.acm.org/class/1998/ccs98-intro.html.
[5] EDVAC (Electronic Discrete Variable Automatic Computer), kolejna wersja po ENIAC komputera elektronicznego, zbudowanego w kwietniu 1952 r.
[6] DENNIG, P. Is computer science science? In Comuncation of the ATM [on-line]. 2005 nr 4 (48) [dostęp 11 maja 2006]. Dostępny w World Wide Web: http://cs.gmu.edu/cne/pjd/PUBS/CACMcols/cacmApr05.pdf.
[7] ILLG, J., ILLG, T. Słownik informatyczny angielsko-polski polsko-angielski. Katowice: Wydaw. Videograf II, 2003. ISBN 83-7183-266-4.
[8] DUCH, W. Fascynujący świat komputerów. Poznań: Wydaw. NAKOM, 1997, s. 25-57. ISBN 83-86969-09-1
[9] AFIPS skrót od American Federation of Information Processing Societes, co oznacza amerykańskie stowarzyszenie zajmujące się problematyką przetwarzania informacji.
[10] Drzewo klasyfikacji dostępne jest na stronie portalu ACM: http://www.acm.org/class/1998/overview.html.
[11] KINGSTON, J. Ontology, Knowledge Management, Knowledge Engineering and the ACM Classification Scheme. In Proceedings of ES’02, the 22nd Annual International Conference of the British Computer Society's Specialist Group on Artificial Intelligenc, Cambridge, 10-12 December 2002 [on-line]. 2002 [ dostęp 20 kwietnia 2006]. Dostępny w World Wide Web: http://www.inf.ed.ac.uk/publications/online/0169.pdf.
[12] Data Mining (w tłumaczeniu „kopanie danych”) – eksploracja, drążenie danych, jest procesem mającym na celu odkrywania nieznanej dotąd wiedzy, jak na przykład wzorów zachowań, zależności między zdarzeniami.
[13] Klaster – grupa (klasa) obiektów, które są do siebie podobne pod względem pewnych cech. Klasteryzacja jest jednym z podstawowych zadań Data Mining.
[14] MALY, K., ZUBAIR, M., ANAN, H. An Automated Classification System and Associated Digital Library Services [on-line], July 2001 [dostęp 27 czerwca 2006 ]. Dostępny World Wide Web: http://www.cs.odu.edu/~anan/publications/nddl.doc.
[15] Ontologia jako sposób formalizacji wiedzy określa strukturę i schemat klasyfikacyjny bazy wiedzy.
[16] Computing Classification System 1998: Current Status and Future Maintenance. Report of the CCS Update Committee. 1998. In Computing Reviews [on-line]. January 1998 [dostęp 20 czerwca 2006]. Dostępny World Wide Web: http://www.acm.org/class/1998/ccsup.pdf.
Poprzedni - Spis treści - Następny![]()
(C) 2006 EBIB
| Współczesna problematyka sposobów klasyfikacji informatyki. Kierunki rozwoju / Veslava Osinska // W: Opracowanie przedmiotowe dokumentów z zakresu nauk ścisłych: matematyczno-przyrodniczych i technicznych. Język haseł przedmiotowych KABA: teoria, praktyka, przyszłość. Kazimierz Dolny, 20-22 września 2006 roku. - [Warszawa] : Stowarzyszenie Bibliotekarzy Polskich, K[omisja] W[ydawnictw] E[lektronicznych], Redakcja "Elektronicznej Biblioteki", 2006. - (EBIB Materiały konferencyjne nr 15). - ISBN 83-921757-6-X. -Tryb dostępu : http://www.ebib.info/publikacje/matkonf/kaba/osinska.php |